 |
|
|
|
Sat, 01 Aug, 2026
|

|

|
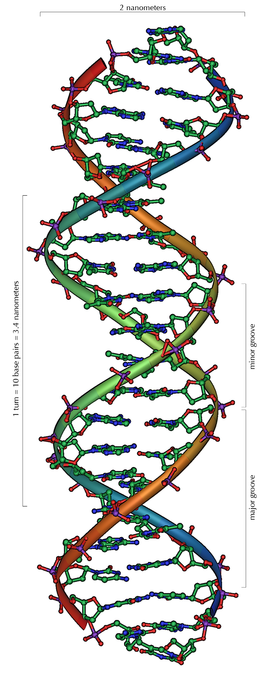 The general structure of a section of DNA
Deoxyribonucleic acid (DNA) is a nucleic acid —usually in the form of a double helix— that contains the genetic instructions specifying the biological development of all cellular forms of life, and most viruses. DNA is a long polymer of nucleotides and encodes the sequence of the amino acid residues in proteins using the genetic code, a triplet code of nucleotides.In complex eukaryotic cells such as those from plants, animals, fungi and protists, most of the DNA is located in the cell nucleus. By contrast, in simpler cells called prokaryotes, including the eubacteria and archaea, DNA is not separated from the cytoplasm by a nuclear envelope. The cellular organelles known as chloroplasts and mitochondria also carry DNA.DNA is often referred to as the molecule of heredity as it is responsible for the genetic propagation of most inherited traits. In humans, these traits can range from hair colour to disease susceptibility. During cell division, DNA is replicated and can be transmitted to offspring during reproduction. Lineage studies can be done based on the facts that the mitochondrial DNA only comes from the mother, and the male Y chromosome only comes from the father.Every person's DNA, their genome, is inherited from both parents. The mother's mitochondrial DNA together with twenty-three chromosomes from each parent combine to form the genome of a zygote, the fertilized egg. As a result, with certain exceptions such as red blood cells, most human cells contain 23 pairs of chromosomes, together with mitochondrial DNA inherited from the mother.
 Jump to Page Contents Jump to Page Contents
|
|

Pay as you go
No monthly charges. Access for the price of a phone call
Go>
Unmetered
Flat rate dialup access from only £4.99 a month Go>
Broadband
Surf faster from just £13.99 a month Go> |
Save Even More
Combine your phone and internet, and save on your phone calls
More Info> |
This weeks hot offer
 24: Series 5
24: Series 5
In association with Amazon.co.uk £26.97 |
|
Contents
Overview
DNA in practice
Molecular structure
Sequence role
Replication
Mechanical biological properties
Strand direction
Single-stranded DNA (ssDNA) and repair of mutations
History of DNA research
Overview - Contents
 Space-filling model of a section of DNA molecule
 DNA Under electron microscope
This section presents an introductory and therefore incomplete overview of DNA.
- Genes can be loosely viewed as the organism's "cookbook" or "blueprint";
- A strand of DNA contains genes, areas that regulate genes, and areas that either have no function, or a function which we do not (yet) know; also see last bullet point in this section for the difference between DNA and RNA;
- DNA is organized as two complementary strands, head-to-toe, with hydrogen bonds between them that can be "unzipped" like a zipper, separating the strands — contrary to a common misconception, DNA is not a single molecule, but rather a pair of molecules joined by these bonds;
- DNA is a chain of chemical "building blocks", called " bases", of which there are four types: these can be abbreviated A, T, C, and G. Each base can only "pair up" with one single predetermined other base: A+T, T+A, C+G and G+C are the only possible combinations; that is, an "A" on one strand of double-stranded DNA will "mate" properly only with a "T" on the other, complementary strand;
- U replaces T, notably in PBS1 phage DNA; U replaces T in RNA.
- The allowable base components of nucleic acids can be polymerized in any order giving the molecules a high degree of uniqueness;
- DNA is an acid because of the phosphate groups between each deoxyribose. This the primary reason why DNA has a negative charge.
- The "polarity" of each pair is important: A+T is not the same as T+A, just as C+G is not the same as G+C (note that "polarity" as such is never used in this context -- it's just a suggestive way to get the idea across);
- For each given base, there is just one possible complementary base, so naming the bases on the conventionally chosen side of the strand is enough to describe the entire double-strand sequence;
- The genetic information contained in a strand of DNA is determined by the sequence of bases along its length;
- The cell begins DNA replication by forcibly unzipping the DNA double strand down the middle, and then recreates the "other half" of each new single strand by exposing each half to a mixture of the four bases. An enzyme makes a new strand by finding the correct base in the mixture and pairing it with the original strand. In this way, the base on the old strand dictates which base will be on the new strand, and the cell ends up with an extra copy of its DNA.
-
Mutations are simply chemical imperfections in this process: a base is accidentally skipped, inserted, or incorrectly copied, or the chain is trimmed, or added to; many basic mutations can be described as combinations of these accidental "operations". Mutations can also occur through chemical damage (through mutagens), light (UV damage), or through other more complicated gene swapping events.
-
DNA molecules that act as enzymes are known in laboratories, but none have been known to be found in life so far.
- In addition to the traditionally viewed duplex form of DNA, DNA can also acquire triplex and quadraplex forms. Here instead of the Watson Crick base pairing, Hoogsten base pairing comes into picture.
- DNA differs from ribonucleic acid (RNA) by having a sugar 2-deoxyribose instead of ribose in its backbone. This is the basic chemical distinction between RNA and DNA.
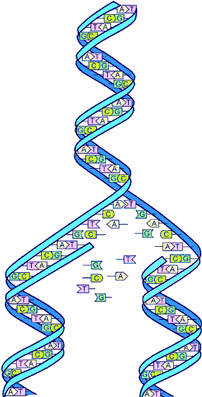
DNA pairing
 DNA base pairing
The paired bases are joined by hydrogen bonds. This image shows the normal base pairing. And also how on rare occasions, wrong pairing can happen, when thymine goes into its enol form or cytosine goes into its imino form.
DNA in practice - Contents
DNA in crime
Forensic scientists can use DNA located in blood, semen, skin, saliva or hair left at the scene of a crime to identify a possible suspect, a process called genetic fingerprinting or DNA profiling. In DNA profiling the relative lengths of sections of repetitive DNA, such as short tandem repeats and minisatellites, are compared. DNA profiling was developed in 1984 by English geneticist Alec Jeffreys, and was first used to convict Colin Pitchfork in 1988 in the Enderby murders case in Leicestershire, England. Many jurisdictions require convicts of certain types of crimes to provide a sample of DNA for inclusion in a computerized database. This has helped investigators solve old cases where the perpetrator was unknown and only a DNA sample was obtained from the scene (particularly in rape cases between strangers). This method is one of the most reliable techniques for identifying a criminal, but is not always perfect, for example if no DNA can be retrieved, or if the scene is contaminated with the DNA of several possible suspects.
DNA in computation
An extremely important note: Despite its biological origins, DNA plays an important role in computer science, both as a motivating research problem and as a method of computation in itself, called DNA computing, not only for biological origins.As a simple example, research on string searching algorithms, which find an occurrence of a sequence of letters inside a larger sequence of letters, was motivated by DNA research, where it is used to find specific sequences of nucleotides in a large sequence. In other applications like text editors, even simple algorithms for this problem usually suffice, but DNA sequences cause these algorithms to exhibit near-worst-case behaviour due to their small number of distinct characters.
Databases have also been strongly motivated by DNA research, which requires special tools for storing and manipulating DNA sequences. Databases specialized for this purpose are called genomic databases, and have a number of unique technical challenges associated with the operations of approximate matching, sequence comparison, finding repeating patterns, and homology searching.In 1994, Leonard Adleman of the University of Southern California made headlines when he discovered a way of solving the directed Hamiltonian path problem, an NP-complete problem, using tools from molecular biology, in particular DNA. The new approach, dubbed DNA computing, has practical advantages over traditional computers in power use, space use, and efficiency, due to its ability to highly parallelize the computation (see parallel computing), although there is labor worth mentioning involved in retrieving the answers. A number of other problems, including simulation of various abstract machines, the boolean satisfiability problem, and the bounded version of the Post correspondence problem, have since been analyzed using DNA computing.Due to its compactness, DNA also has a theoretical role in cryptography, where in particular it allows unbreakable one-time pads to be efficiently constructed and used [1].
DNA in historical and anthropological study
DNA research is also used to follow the course of human populations over time.DNA evidence is also being used to try to identify the Ten Lost Tribes of Israel [2] [3]DNA has also been used to look at fairly recent issues of family relationships, such as establishing some manner of familial relationship between the descendents of Sally Hemings and the family of Thomas Jefferson.
Molecular structure - Contents
 Comparisons between DNA and single stranded RNA with the diagram of the bases showing.
Although sometimes called "the molecule of heredity", DNA macromolecules as people typically think of them are not single molecules. Rather, they are pairs of molecules, which entwine like vines to form a double helix (see the illustration at the right).Each vine-like molecule is a strand of DNA: a chemically linked chain of nucleotides, each of which consists of a sugar ( deoxyribose), a phosphate and one of five kinds of nucleobases ("bases"). Because DNA strands are composed of these nucleotide subunits, they are polymers.The diversity of the bases means that there are five kinds of nucleotides, which are commonly referred to by the identity of their bases. These are adenine (A), thymine (T), uracil (U), cytosine (C), and guanine (G). U is rarely found in DNA except as a result of chemical degradation of C, but in some viruses, notably PBS1 phage DNA, U completely replaces the usual T in its DNA. Similarly, RNA usually contains U in place of T, but in certain RNAs such as transfer RNA, T is always found in some positions. Thus, the only true difference between DNA and RNA is the sugar, 2-deoxyribose in DNA and ribose in RNA.In a DNA double helix, two polynucleotide strands can associate through the hydrophobic effect and pi stacking. Specificity of which strands stay associated is determined by complementary pairing. Each base forms hydrogen bonds readily to only one other -- A to T and C to G -- so that the identity of the base on one strand dictates the strength of the association; the more complementary bases exist, the stronger and longer-lasting the association.The cell's machinery is capable of melting or disassociating a DNA double helix, and using each DNA strand as a template for synthesizing a new strand which is nearly identical to the previous strand. Errors that occur in the synthesis are known as mutations. The process known as PCR (polymerase chain reaction) mimics this process in vitro in a nonliving system.Because pairing causes the nucleotide bases to face the helical axis, the sugar and phosphate groups of the nucleotides run along the outside; the two chains they form are sometimes called the "backbones" of the helix. In fact, it is chemical bonds between the phosphates and the sugars that link one nucleotide to the next in the DNA strand.
 |
|
Rotating DNA stick model ( info) |
| Animation of a section of DNA rotating. (1.00 MB, animated GIF format). |
| Problems seeing the videos? Media help. |
|
Sequence role - Contents
Within a gene, the sequence of nucleotides along a DNA strand defines a messenger RNA sequence which then defines a protein, that an organism is liable to manufacture or " express" at one or several points in its life using the information of the sequence. The relationship between the nucleotide sequence and the amino-acid sequence of the protein is determined by simple cellular rules of translation, known collectively as the genetic code. The genetic code is made up of three-letter 'words' (termed a codon) formed from a sequence of three nucleotides (e.g. ACT, CAG, TTT). These codons can then be translated with messenger RNA and then transfer RNA, with a codon corresponding to a particular amino acid. There are 64 possible codons (4 bases in 3 places 43) that encode 20 amino acids. Most amino acids, therefore, have more than one possible codon. There are also three 'stop' or 'nonsense' codons signifying the end of the coding region, namely the UAA, UGA and UAG codons.In many species, only a small fraction of the total sequence of the genome appears to encode protein. For example, only about 1.5% of the human genome consists of protein-coding exons. The function of the rest is a matter of speculation. It is known that certain nucleotide sequences specify affinity for DNA binding proteins, which play a wide variety of vital roles, in particular through control of replication and transcription. These sequences are frequently called regulatory sequences, and researchers assume that so far they have identified only a tiny fraction of the total that exist. " Junk DNA" represents sequences that do not yet appear to contain genes or to have a function. The reasons for the presence of so much non-coding DNA in eukaryotic genomes and the extraordinary differences in genome size (" C-value") among species represent a long-standing puzzle in DNA research known as the " C-value enigma".Some DNA sequences play structural roles in chromosomes. Telomers and centromeres typically contain few (if any) protein-coding genes, but are important for the function and stability of chromosomes. Some genes code for "RNA genes" (see tRNA and rRNA). Some RNA genes code for transcripts that function as regulatory RNAs (see siRNA) that influence the function of other RNA molecules. The intron-exon structure of some genes (such as immunoglobin and protocadeherin genes) is important for allowing alternative splicing of pre-mRNA which allows several different proteins to be made from the same gene. Some non-coding DNA represents pseudogenes that can be used as raw material for the creation of new genes with new functions. Some non-coding DNA provided hot-spots for duplication of short DNA regions; such sequence duplication has been the major form of genetic change in the human lineage (see evidence from the Chimpanzee Genome Project). Exons interspersed with introns allows for "exon shuffling" and the creation of modified genes that might have new adaptive functions. Large amounts of non-coding DNA is probably adaptive in that it provides chromosomal regions where recombination between homologous portions of chromosomes can take place without disrupting the function of genes. Some biologists such as Stuart Kauffman have speculated that non-coding DNA may modify the rate of evolution of a species.[ citation needed]Sequence also determines a DNA segment's susceptibility to cleavage by restriction enzymes, the quintessential tools of genetic engineering. The position of cleavage sites throughout an individual's genome determines one kind of an individual's " DNA fingerprint".
Replication - Contents
 DNA replication
DNA replication or DNA synthesis is the process of copying the double-stranded DNA prior to cell division. The two resulting double strands are generally almost perfectly identical, but occasionally errors in replication or exposure to chemicals, or radiation can result in a less than perfect copy (see mutation), and each of them consists of one original and one newly synthesized strand. This is called semiconservative replication. The process of replication consists of three steps: initiation, elongation and termination.
Mechanical biological properties - Contents
Strands association and dissociation
The hydrogen bonds between the strands of the double helix are weak enough that they can be easily separated by enzymes. Enzymes known as helicases unwind the strands to facilitate the advance of sequence-reading enzymes such as DNA polymerase. The unwinding requires that helicases chemically cleave the phosphate backbone of one of the strands so that it can swivel around the other. The strands can also be separated by gentle heating, as used in PCR, provided they have fewer than about 10,000 base pairs (10 kilobase pairs, or 10 kbp). The intertwining of the DNA strands makes long segments difficult to separate.
Circular DNA
When the ends of a piece of double-helical DNA are joined so that it forms a circle, as in plasmid DNA, the strands are topologically knotted. This means they cannot be separated by gentle heating or by any process that does not involve breaking a strand. The task of unknotting topologically linked strands of DNA falls to enzymes known as topoisomerases. Some of these enzymes unknot circular DNA by cleaving two strands so that another double-stranded segment can pass through. Unknotting is required for the replication of circular DNA as well as for various types of recombination in linear DNA.
Great length versus tiny breadth
The narrow breadth of the double helix makes it impossible to detect by conventional electron microscopy, except by heavy staining. At the same time, the DNA found in many cells can be macroscopic in length -- approximately 2 meters long for strands in a human chromosome [4]. Consequently, cells must compact or "package" DNA to carry it within them. This is one of the functions of the chromosomes, which contain spool-like proteins known as histones, around which DNA winds.
Entropic stretching behaviour
When DNA is in solution, it undergoes conformational fluctuations due to the energy available in the thermal bath. For entropic reasons, more floppy states are thermally accessible than stretched out states; for this reason, a single molecule of DNA stretches similarly to a rubber band. Using optical tweezers, the entropic stretching behaviour of DNA has been studied and analyzed from a polymer physics perspective, and it has been found that DNA behaves like the Kratky-Porod worm-like chain model with a persistence length of about 53 nm.Furthermore, DNA undergoes a stretching phase transition at a force of 65 pN; above this force, DNA is thought to take the form that Linus Pauling originally hypothesized, with the phosphates in the middle and bases splayed outward. This proposed structure for overstretched DNA has been called "P-form DNA," in honor of Pauling.
Different helix geometries
The DNA helix can assume one of three slightly different geometries, of which the "B" form described by James D. Watson and Francis Crick is believed to predominate in cells. It is 2 nanometres wide and extends 3.4 nanometres per 10 bp of sequence. This is also the approximate length of sequence in which the double helix makes one complete turn about its axis. This frequency of twist (known as the helical pitch) depends largely on stacking forces that each base exerts on its neighbors in the chain.Supercoiled DNA
The B form of the DNA helix twists 360° per 10 bp in the absence of strain. But many molecular biological processes can induce strain. A DNA segment with excess or insufficient helical twisting is referred to, respectively, as positively or negatively " supercoiled". DNA in vivo is typically negatively supercoiled, which facilitates the unwinding of the double-helix required for RNA transcription.Sugar pucker
There are four conformations that the ribofuranose rings in nucleotides can acquire:
- C-2' endo
- C-2' exo
- C-3' endo
- C-3' exo
Ribose is usually in C-3'endo, while deoxyribose is usually in the C-2' endo sugar pucker conformation. The A and B forms differ mainly in their sugar pucker. In the A form, the C3' configuration is above the sugar ring, whilst the C2' configuration is below it. Thus, the A form is described as "C3'-endo." Likewise, in the B form, the C2' configuration is above the sugar ring, whilst C3' is below; this is called "C2'-endo." Altered sugar puckering in A-DNA results in shortening the distance between adjacent phosphates by around one angstrom. This gives 11 to 12 base pairs to each helix in the DNA strand, instead of 10.5 in B-DNA. Sugar pucker gives uniform ribbon shape to DNA, a cylindrical open core, and also a deep major groove more narrow and pronounced that grooves found in B-DNA.A and Z helices formation
The two other known double-helical forms of DNA, called A and Z, differ modestly in their geometry and dimensions. The A form appears likely to occur only in dehydrated samples of DNA, such as those used in crystallographic experiments, and possibly in hybrid pairings of DNA and RNA strands. Segments of DNA that cells have methylated for regulatory purposes may adopt the Z geometry, in which the strands turn about the helical axis like a mirror image of the B form.Properties of different helical forms
| Geometry attribute |
A-form |
B-form |
Z-form |
| Helix sense |
right-handed |
right-handed |
left-handed |
| Repeating unit |
1 bp |
1 bp |
2 bp |
| Rotation/bp |
33.6° |
35.9° |
60°/2 |
| Mean bp/turn |
10.7 |
10.4 |
12 |
| Inclination of bp to axis |
+19° |
-1.2° |
-9° |
| Rise/bp along axis |
0.23 nm |
0.332 nm |
0.38 nm |
| Pitch/turn of helix |
2.46 nm |
3.32 nm |
4.56 nm |
| Mean propeller twist |
+18° |
+16° |
0° |
| Glycosyl angle |
anti |
anti |
C: anti,
G: syn |
| Sugar pucker |
C3'-endo |
C2'-endo |
C: C2'-endo,
G: C2'-exo |
| Diameter |
2.6 nm |
2.0 nm |
1.8 nm |
Non-helical forms
Other, including non-helical, forms of DNA have been described, for example a side-by-side (SBS) configuration. Indeed, it is far from certain that the B-form double helix is the dominant form in living cells.A detailed study of the experimental results remaining to be explained by the double helix model is set out in a whole book freely available as a pdf file from:
http://www.notahelix.com/delmonte/new_struct_mol_biol.pdfand a recent research paper summarises some key experimental data which are better explained by SBS models than by the double helix:
http://www.ias.ac.in/currsci/dec102003/1564.pdfwith subsequent correspondence:
http://www.ias.ac.in/currsci/may252004/1352.pdf
Strand direction - Contents
The asymmetric shape and linkage of nucleotides means that a DNA strand always has a discernible orientation or directionality. Because of this directionality, close inspection of a double helix reveals that nucleotides are heading one way along one strand (the "ascending strand"), and the other way along the other strand (the "descending strand"). This arrangement of the strands is called antiparallel.
Chemical nomenclature ( 5' and 3')
For reasons of chemical nomenclature, people who work with DNA refer to the asymmetric ends of ("five prime" and "three prime"). Within a cell, the enzymes that perform replication and transcription read DNA in the " 3' to 5' direction", while the enzymes that perform translation read in the opposite direction (on RNA). However, because chemically produced DNA is synthesized and manipulated in the opposite or in non-directional manners, the orientation should not be assumed. In a vertically oriented double helix, the 3' strand is said to be ascending while the 5' strand is said to be descending.
Sense and antisense
As a result of their antiparallel arrangement and the sequence-reading preferences of enzymes, even if both strands carried identical instead of complementary sequences, cells could properly translate only one of them. The other strand a cell can only read backwards. Molecular biologists call a sequence "sense" if it is translated or translatable, and they call its complement "antisense". It follows then, somewhat paradoxically, that the template for transcription is the antisense strand. The resulting transcript is an RNA replica of the sense strand and is itself sense.
Distinction between sense and antisense strands
A small proportion of genes in prokaryotes, and more in plasmids and viruses, blur the distinction made above between sense and antisense strands. Certain sequences of their genomes do double duty, encoding one protein when read 5' to 3' along one strand, and a second protein when read in the opposite direction (still 5' to 3') along the other strand. As a result, the genomes of these viruses are unusually compact for the number of genes they contain, which biologists view as an adaptation. This merely confirms that there is no biological distinction between the two strands of the double helix. Indeed, typically each strand of a DNA double helix will act as sense and antisense in different regions.
As viewed by topologists
Topologists like to note that the juxtaposition of the 3′ end of one DNA strand beside the 5′ end of the other at both ends of a double-helical segment makes the arrangement a " crab canon".
Single-stranded DNA (ssDNA) and repair of mutations - Contents
In some viruses DNA appears in a non-helical, single-stranded form. Because many of the DNA repair mechanisms of cells work only on paired bases, viruses that carry single-stranded DNA genomes mutate more frequently than they would otherwise. As a result, such species may adapt more rapidly to avoid extinction. The result would not be so favorable in more complicated and more slowly replicating organisms, however, which may explain why only viruses carry single-stranded DNA. These viruses presumably also benefit from the lower cost of replicating one strand versus two.
History of DNA research - Contents

James Watson in the Cavendish Laboratory at the University of Cambridge
The discovery that DNA was the carrier of genetic information was a process that required many earlier discoveries. The existence of DNA was discovered in the mid 19th century. However, it was only in the early 20th century that researchers began suggesting that it might store genetic information. This was only accepted after the structure of DNA was elucidated by James D. Watson and Francis Crick in their 1953 Nature publication. Watson and Crick proposed the central dogma of molecular biology in 1957, describing the process whereby proteins are produced from nucleic DNA. In 1962 Watson, Crick, and Maurice Wilkins jointly received the Nobel Prize for their determination of the structure of DNA.
First isolation of DNA
Working in the 19th century, biochemists initially isolated DNA and RNA (mixed together) from cell nuclei. They were relatively quick to appreciate the polymeric nature of their "nucleic acid" isolates, but realized only later that nucleotides were of two types--one containing ribose and the other deoxyribose. It was this subsequent discovery that led to the identification and naming of DNA as a substance distinct from RNA.
Friedrich Miescher (1844-1895) discovered a substance he called "nuclein" in 1869. Somewhat later, he isolated a pure sample of the material now known as DNA from the sperm of salmon, and in 1889 his pupil, Richard Altmann, named it "nucleic acid". This substance was found to exist only in the chromosomes.In 1929 Phoebus Levene at the Rockefeller Institute identified the components (the four bases, the sugar and the phosphate chain) and he showed that the components of DNA were linked in the order phosphate-sugar-base. He called each of these units a nucleotide and suggested the DNA molecule consisted of a string of nucleotide units linked together through the phosphate groups, which are the 'backbone' of the molecule. However Levene thought the chain was short and that the bases repeated in the same fixed order. Torbjorn Caspersson and Einar Hammersten showed that DNA was a polymer.
Chromosomes and inherited traits
Max Delbrück, Nikolai V. Timofeeff-Ressovsky, and Karl G. Zimmer published results in 1935 suggesting that chromosomes are very large molecules the structure of which can be changed by treatment with X-rays, and that by so changing their structure it was possible to change the heritable characteristics governed by those chromosomes. In 1937 William Astbury produced the first X-ray diffraction patterns from DNA. He was not able to propose the correct structure but the patterns showed that DNA had a regular structure and therefore it might be possible to deduce what this structure was.In 1943, Oswald Theodore Avery and a team of scientists discovered that traits proper to the "smooth" form of the Pneumococcus could be transferred to the "rough" form of the same bacteria merely by making the killed "smooth" (S) form available to the live "rough" (R) form. Quite unexpectedly, the living R Pneumococcus bacteria were transformed into a new strain of the S form, and the transferred S characteristics turned out to be heritable. Avery called the medium of transfer of traits the transforming principle; he identified DNA as the transforming principle, and not protein as previously thought. He essentially redid Fredrick Griffith's experiment. In 1953, Alfred Hershey and Martha Chase did an experiment (Hershey-Chase experiment) that showed, in T2 phage, that DNA is the genetic material (Hershey shared the Nobel prize with Luria).
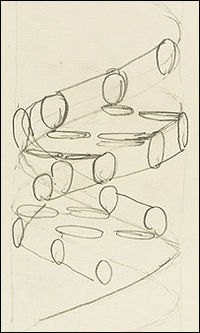
Francis Crick's first sketch of the deoxyribonucleic acid double-helix pattern
In 1944, the renowned physicist, Erwin Schrödinger, published a brief book entitled What is Life?, where he maintained that chromosomes contained what he called the "hereditary code-script" of life. He added: "But the term code-script is, of course, too narrow. The chromosome structures are at the same time instrumental in bringing about the development they foreshadow. They are law-code and executive power -- or, to use another simile, they are architect's plan and builder's craft -- in one." He conceived of these dual functional elements as being woven into the molecular structure of chromosomes. By understanding the exact molecular structure of the chromosomes one could hope to understand both the "architect's plan" and also how that plan was carried out through the "builder's craft." Three groups took up Schrödinger's challenge to work out the structure of the chromosomes and the question of how the segments of the chromosomes that were conceived to relate to specific traits could possibly do their jobs.Just how the presence of specific features in the molecular structure of chromosomes could produce traits and behaviors in living organisms was unimaginable at the time. Because chemical dissection of DNA samples always yielded the same four nucleotides, the chemical composition of DNA appeared simple, perhaps even uniform. Organisms, on the other hand, are fantastically complex individually and widely diverse collectively. Geneticists did not speak of genes as conveyors of "information" in such words, but if they had, they would not have hesitated to quantify the amount of information that genes need to convey as vast. The idea that information might reside in a chemical in the same way that it exists in text--as a finite alphabet of letters arranged in a sequence of unlimited length--had not yet been conceived. It would emerge upon the discovery of DNA's structure, but few researchers imagined that DNA's structure had much to say about genetics.
Discovery of the structure of DNA
In the 1950s, three groups made it their goal to determine the structure of DNA. The first group to start was at King's College London and was led by Maurice Wilkins and was later joined by Rosalind Franklin. Another group consisting of Francis Crick and James D. Watson was at Cambridge. A third group was at Caltech and was led by Linus Pauling. Crick and Watson built physical models using metal rods and balls, in which they incorporated the known chemical structures of the nucleotides, as well as the known position of the linkages joining one nucleotide to the next along the polymer. At King's College Maurice Wilkins and Rosalind Franklin examined X-ray diffraction patterns of DNA fibers. Of the three groups, only the London group was able to produce good quality diffraction patterns and thus produce sufficient quantitative data about the structure.
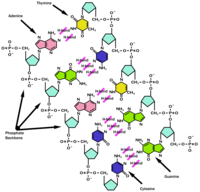 The chemical structure of DNA
Helix structure
In 1948 Pauling discovered that many proteins included helical (see alpha helix) shapes. Pauling had deduced this structure from X-ray patterns. (Pauling was also later to suggest an incorrect three chain helical structure based on Astbury's data.) Even in the initial diffraction data from DNA by Maurice Wilkins, it was evident that the structure involved helices. But this insight was only a beginning. There remained the questions of how many strands came together, whether this number was the same for every helix, whether the bases pointed toward the helical axis or away, and ultimately what were the explicit angles and coordinates of all the bonds and atoms. Such questions motivated the modeling efforts of Watson and Crick.Complementary nucleotides
In their modeling, Watson and Crick restricted themselves to what they saw as chemically and biologically reasonable. Still, the breadth of possibilities was very wide. A breakthrough occurred in 1952, when Erwin Chargaff visited Cambridge and inspired Crick with a description of experiments Chargaff had published in 1947. Chargaff had observed that the proportions of the four nucleotides vary between one DNA sample and the next, but that for particular pairs of nucleotides -- adenine and thymine, guanine and cytosine -- the two nucleotides are always present in equal proportions.Watson and Crick's model
 Crick and Watson DNA model built in 1953, currently on display at the National Science Museum in London.
Watson and Crick had begun to contemplate double helical arrangements, but they lacked information about the amount of twist (pitch) and the distance between the two strands. Rosalind Franklin had to disclose some of her findings for the Medical Research Council and Crick saw this material through Max Perutz's links to the MRC. Franklin's work confirmed a double helix that was on the outside of the molecule and also gave an insight into its symmetry, in particular that the two helical strands ran in opposite directions.Watson and Crick were again greatly assisted by more of Franklin's data. This is controversial because Franklin's critical X-ray pattern was shown to Watson and Crick without Franklin's knowledge or permission. Wilkins showed the famous Photo 51 to Watson at his lab immediately after Watson had been unsuccessful in asking Franklin to collaborate to beat Pauling in finding the structure.From the data in photograph 51 Watson and Crick were able to discern that not only was the distance between the two strands was constant, but also to measure its exact value of 2 nanometres. The same photograph also gave them the 3.4 nanometre-per-10 bp "pitch" of the helix.The final insight came when Crick and Watson saw that a complementary pairing of the bases could provide an explanation for Chargaff's puzzling finding. However the structure of the bases had been incorrectly guessed in the textbooks as the enol tautomer when they were more likely to be in the keto form. When Jerry Donohue pointed this fallacy out to Watson, Watson quickly realised that the pairs of adenine and thymine, and guanine and cytosine were almost identical in shape and so would provide equally sized 'rungs' between the two strands. With the base-pairing, the Watson and Crick quickly converged upon a model, which they announced before Franklin herself had published any of her work.Franklin was two steps away from the solution. She had not guessed the base-pairing and had not appreciated the implications of the symmetry that she had described. However she had been working almost alone and did not have regular contact with a partner like Crick and Watson, and with other experts such as Jerry Donohoe. Her notebooks show that she was aware both of Jerry Donohue's work concerning tautomeric forms of bases (she had used the keto forms for three of the bases) and of Chargaff's work.The disclosure of Franklin's data to Watson has angered some people who believe Franklin did not receive due credit at the time and that she might have discovered the structure on her own before Crick and Watson. In Crick and Watson's famous paper in Nature in 1953, they said that their work had been stimulated by the work of Wilkins and Franklin, whereas it had been the basis of their work. However they had agreed with Wilkins and Franklin that they all should publish papers in the same issue of Nature in support of the proposed structure."Central Dogma"
Watson and Crick's model attracted great interest immediately upon its presentation. Arriving at their conclusion on February 21, 1953, Watson and Crick made their first announcement on February 28. Their paper 'A Structure for Deoxyribose Nucleic Acid' was published on April 25. In an influential presentation in 1957, Crick laid out the " Central Dogma", which foretold the relationship between DNA, RNA, and proteins, and articulated the "sequence hypothesis." A critical confirmation of the replication mechanism that was implied by the double-helical structure followed in 1958 in the form of the Meselson-Stahl experiment. Work by Crick and coworkers showed that the genetic code was based on non-overlapping triplets of codons, and Har Gobind Khorana and others deciphered the genetic code not long afterward. These findings represent the birth of molecular biology.
Watson, Crick, and Wilkins were awarded the 1962 Nobel Prize for Physiology or Medicine for discovering the molecular structure of DNA, by which time Franklin had died from cancer, at the age of 37. Nobel prizes are not awarded posthumously; had she lived, the difficult decision over whom to jointly award the prize would have been complicated as the prize can only be shared between two or three. |
Change Text Size:
[A]
[default]
[A] |


 |
|
|
|
|